Abstract
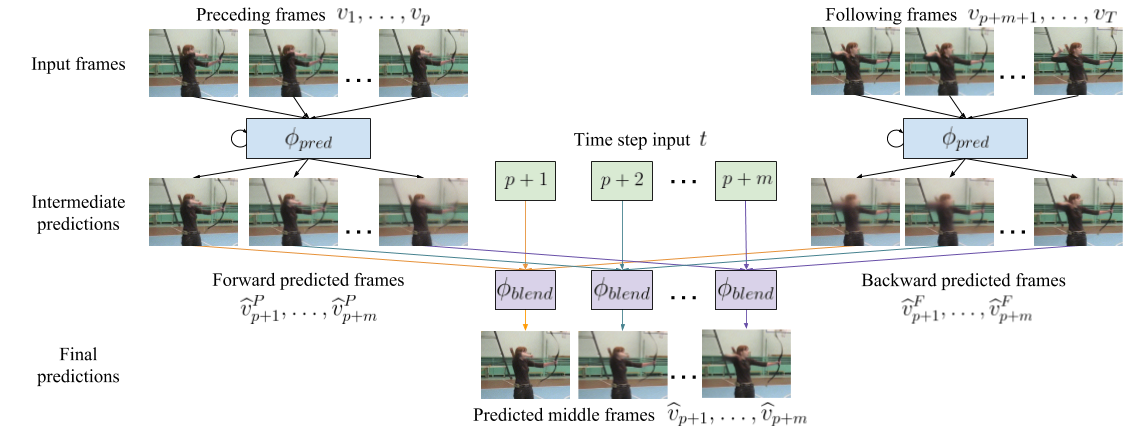
We propose the first deep learning solution to video frame inpainting, a challenging instance of the general video inpainting problem with applications in video editing, manipulation, and forensics. Our task is less ambiguous than frame interpolation and video prediction because we have access to both the temporal context and a partial glimpse of the future, allowing us to better evaluate the quality of a model’s predictions objectively. We devise a pipeline composed of two modules: a bidirectional video prediction module, and a temporally-aware frame interpolation module. The prediction module makes two intermediate predictions of the missing frames, one conditioned on the preceding frames and the other conditioned on the following frames, using a shared convolutional LSTM-based encoder-decoder. The interpolation module blends the intermediate predictions to form the final result. Specifically, it utilizes time information and hidden activations from the video prediction module to resolve disagreements between the predictions. Our experiments demonstrate that our approach produces more accurate and qualitatively satisfying results than a state-of-the-art video prediction method and many strong frame inpainting baselines.
[ arXiv ] [ code ] [ PAMI submission ]
Publications
|
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020
[ BibTeX ]
|
|
Asian Conference on Computer Vision, 2018
[ BibTeX ]
|